生成机器学习数据集
本章介绍如何使用 OghmaNano 生成机器学习数据集。 通常,这些数据集会被导出并使用外部框架(例如 TensorFlow)进行处理,以用于训练、推理或预测。
1. 介绍
通常希望通过建模从实验数据中提取器件物理参数。 例如,可能有一组 JV 曲线,并希望确定器件的电荷载流子迁移率 和复合速率。 传统上,这是通过将基于物理的模型(例如 OghmaNano)拟合到数据上来实现的 (如 拟合教程 中所述)。 这种方法的缺点是拟合单个数据集可能非常耗时,而当必须分析多个数据集时, 难度会显著增加。 拟合过程较为复杂,通常需要相当丰富的数值仿真专业知识, 以及大量人工干预。 因此,详细的器件拟合通常只由社区中相对较小的一部分人完成。
一种更现代的方法是使用机器学习。 与其直接拟合单条 JV 曲线,不如首先构建一个表示 器件结构的仿真。 不再优化单个电学参数,而是生成成千上万个该器件的副本, 每个副本都具有随机选择的参数值。 这些实例中的每一个都称为一个虚拟器件。 然后使用诸如 OghmaNano 之类的仿真程序为每个虚拟器件生成 JV 曲线, 从而产生一个由 JV 曲线及其对应电学参数配对组成的数据集。 这些数据可用于训练机器学习模型,以直接从 JV 特性中预测电学参数。 在这一框架中,OghmaNano 充当前向变换,将电学参数映射到模拟实验数据, 而机器学习模型则提供逆变换。 一旦训练完成,该模型就可用于从真实器件中提取材料参数。
这种方法的关键优势在于,一旦完成训练,机器学习模型就可以在几秒钟内 从实验数据中提取材料参数,而不要求用户是数值仿真方面的专家。 然而,这种方法能否成功在很大程度上取决于能否生成 大规模、高质量的训练数据集。 使用 OghmaNano 构建此类数据集的过程将在以下页面中说明。
2. 打开示例
本页讨论的示例可通过主窗口中的 New simulation 按钮访问。 这会打开 New simulation 浏览器,如 ?? 所示。
在可用仿真类别列表中,双击 Machine learning 以显示 机器学习示例 (??)。 选择 PM6:Y6 ML example 将加载一个预先配置好的仿真,对应于本章中讨论的器件 和工作流程。
打开后,该仿真将呈现与本节中使用的相同器件结构和自动化设置, 并且无需进一步配置即可直接用于生成机器学习训练数据。


3. 定义仿真和输出向量
打开示例仿真后,您将看到如 图 ?? 所示的主仿真窗口。 该窗口显示了本章中使用的完整配置器件结构。 在 Automation 功能区中,可以看到一个 Machine learning 图标,以蓝色圆形符号表示。单击该图标会打开 图 ?? 所示的主机器学习控制窗口。 从该窗口中可以配置并执行机器学习训练数据的生成。
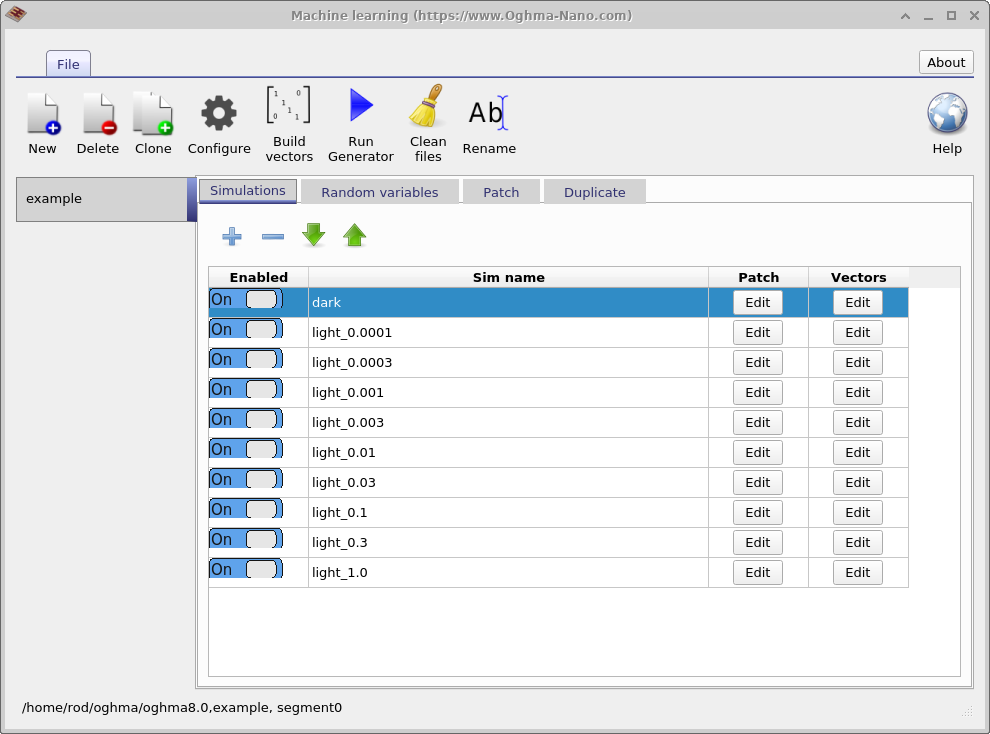
该窗口的主要用途是为训练机器学习算法生成大型数据集。 本示例中生成的数据集名为 example。 显示的第一个选项卡是 Simulations 选项卡,它定义为每个 虚拟器件执行的仿真集合。 在本例中,将模拟一条暗态 JV 曲线和九条受光照 JV 曲线,光强范围从 0.0001 Suns 到 1.0 Suns。 各个仿真可通过 Enabled 开关启用或禁用。 如果在 \(light\_0.0001\) 条目的 Patch 列中单击 Edit 按钮,则会打开 ?? 所示的 Patch window。
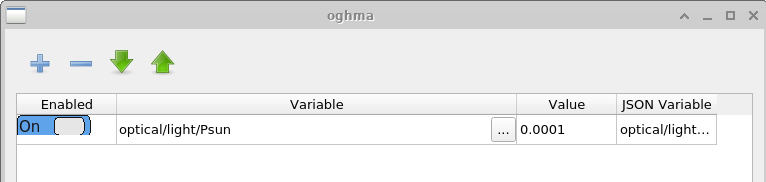
Patch window 的作用是修改虚拟仿真中的参数。 在本示例中,使用相同的 基础器件结构在不同照明条件下生成多条 JV 曲线。 为实现这一点,必须为每个仿真独立调节光强。 打开 \(light\_0.0001\) 的 patch 窗口可见,控制照明强度的仿真 参数 optical/light/Psun 被设置为 \(0.0001\)。 对于 dark 仿真,同一参数被设置为 \(0.0\)。 通过这种方式,可以使用单个基础 仿真一致地模拟多个实验条件。
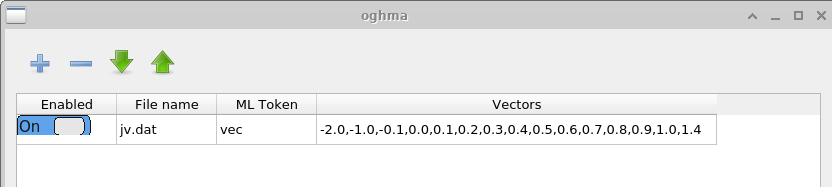
Vectors 窗口定义从已完成仿真中提取哪些数据来构成 机器学习输入向量。 在本示例中,从文件 \(jv.dat\) 中提取 −2.0 V 到 1.4 V 之间的数据点, 该文件包含模拟的电流–电压特性。 对于时域仿真,用户也可以改为从诸如 \(time\_i.csv\) 或任何其他合适的输出文件中提取数据。 用于构建每个输入向量的点数由用户选择。 更长的向量会增加训练的计算成本,但可能捕获 JV 曲线中更详细的特征。
4. 定义随机变量
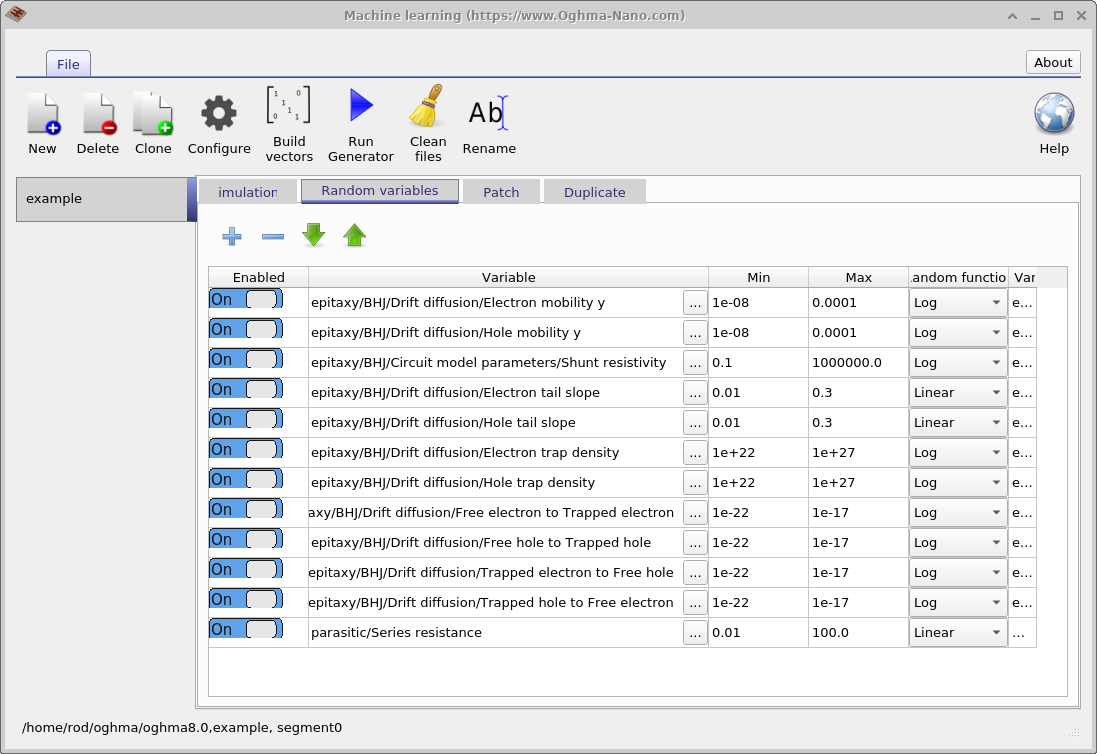
下一步是定义哪些模型参数需要随机化。 这是通过主机器学习窗口中的 Random variables 选项卡完成的。 该表包含五列。 Enabled 列决定某个参数是否包含在随机化过程中。 Variable 列指定被变化的仿真参数。 Min 和 Max 列定义参数范围的下限和上限, 而 Random function 列则指定数值是从线性分布还是对数分布中抽取。
对于跨越多个数量级的参数,建议使用对数分布; 对于变化范围相对较窄的参数,则适合使用线性分布。 使用对数分布可确保当以对数尺度观察时,取值是均匀采样的, 而不是集中在范围的上端。 例如,一个合适的线性参数是 Urbach 能量, 它通常在 30 到 150 meV 之间变化。 相比之下,陷阱密度非常适合对数采样,因为它们可能在 \(1 \times 10^{15}\,\mathrm{m^{-3}}\) 到 \(1 \times 10^{25}\,\mathrm{m^{-3}}\) 之间变化。
5. 定义仿真数量
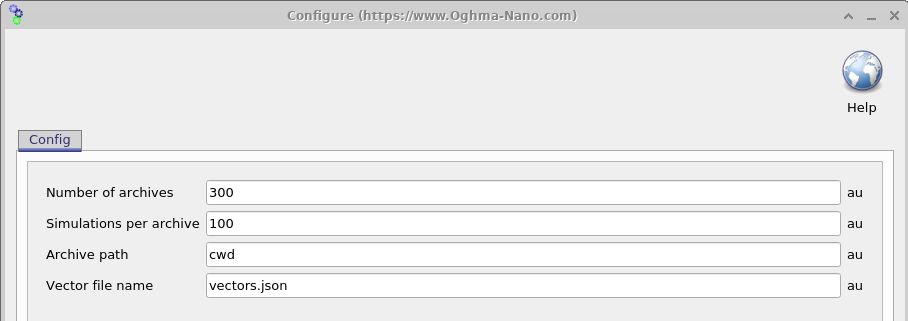
一旦仿真配置完成,下一步就是确定要生成多少个带有 随机化参数的虚拟器件。 打开 Settings window(见 18.6) 后,可以通过两个参数控制: Simulations per archive(\(N_{\mathrm{sim}}\))和 Number of archives(\(N_{\mathrm{arc}}\))。 生成的虚拟器件总数为 \(N_{\mathrm{sim}} \times N_{\mathrm{arc}}\)。
仿真结果会写入称为归档文件的 ZIP 文件中,每个归档文件包含 \(N_{\mathrm{sim}}\) 个虚拟器件。 在此处所示示例中, \(N_{\mathrm{sim}} \times N_{\mathrm{arc}} = 3000\) 个虚拟器件被生成并存储在 100 个归档文件中。 需要注意的是,在这个示例中,每个虚拟器件由一个暗态 JV 仿真和 九个受光照 JV 仿真组成。 因此,输出文件总数会迅速增长。
为管理这一问题,数据生成以批处理方式执行。 一组 \(N_{\mathrm{sim}}\) 个仿真由 OghmaNano 生成并运行, 然后写入单个归档文件,如此重复进行,直到生成 \(N_{\mathrm{arc}}\) 个归档文件为止。 如果过程被中断,这种方式会将数据损失限制在当前正在生成的归档文件内, 同时也简化了文件传输并提高了抗损坏能力。 仿真执行会并行分布到所有可用 CPU 核心上, 而归档创建则在单个核心上执行。
6. 运行数据集生成器
一旦配置完成,在主 Machine learning 窗口中按下 Run generator 按钮 (18.2) 即可启动数据集生成过程。 OghmaNano 随后将开始执行为每个虚拟器件定义的仿真。 当过程结束后,仿真目录中将出现一个名为 example 的目录, 如 18.8 左侧所示。 为了本示例的目的,Simulations per archive 被设为 10,而 Number of archives 被设为 3,以缩短运行时间。
仿真过程中遇到的任何错误都会写入文件 errors.dat。 打开 archive0.zip 可看到归档文件的内部结构,如 18.8 右侧所示。 每个归档文件都包含一组目录,其中每个目录对应一个 虚拟器件。
这些目录以随机的 16 位十六进制标识符命名。 每个目录都包含一个虚拟器件的完整仿真集合; 在本例中,为一个暗态 JV 仿真和九个受光照 JV 仿真。 其中一个目录的内容显示在 18.10 左侧。 打开单个仿真目录 (18.10,右) 可看到一个完整的 OghmaNano 仿真,包括 sim.json 文件以及 包含模拟电流–电压特性的 jv.dat 文件。 也可能还存在额外数据,例如光学输出和缓存文件。
在生成大型机器学习数据集时,强烈建议尽量减少不必要的输出, 因为总磁盘使用量可能会迅速增长。 这可以通过将仿真配置为只生成必要的输出数据来实现。 数据集生成以批处理方式执行,仿真在所有可用 CPU 核心上并行运行, 而归档创建则由单个核心处理。
在这个说明性示例中,只生成了三个归档文件。 然而,在典型的生产运行中,通常会生成大约 200 个归档文件,每个归档文件包含大约 200 个虚拟器件。
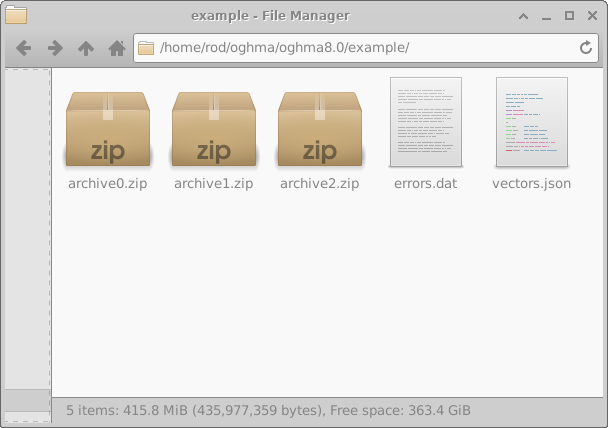
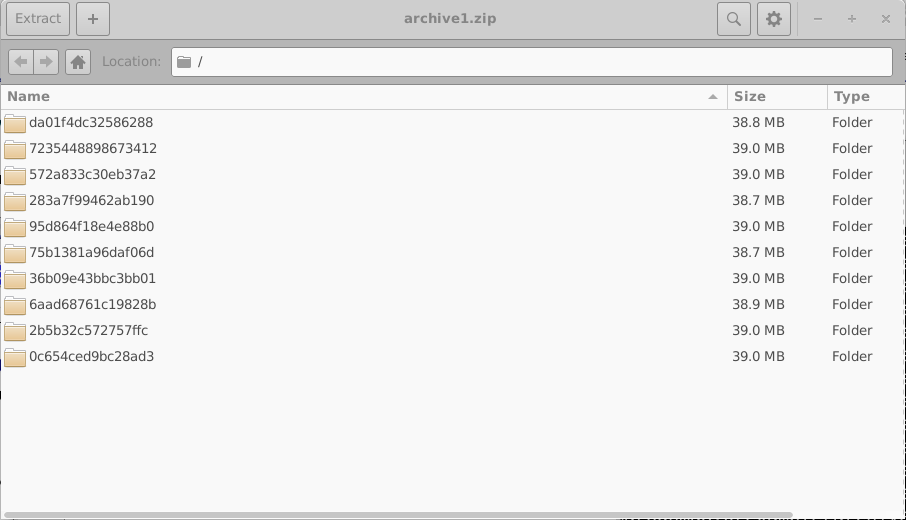
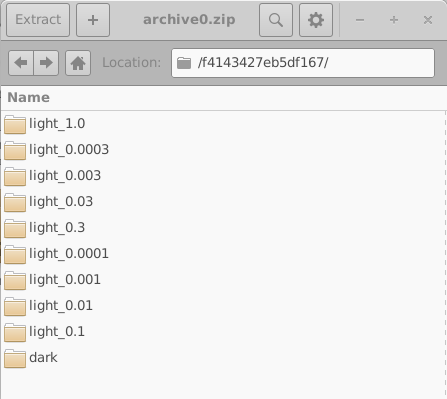
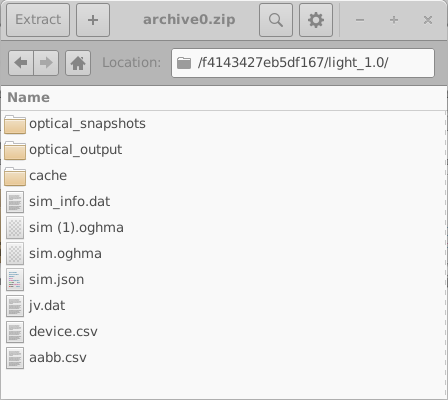
在上面的示例中我们只有三个归档文件,但在正常仿真运行中,通常会有多达 200 个 归档文件,并且每个归档文件中有 200 个仿真。
7. 将结果编译为单个文件
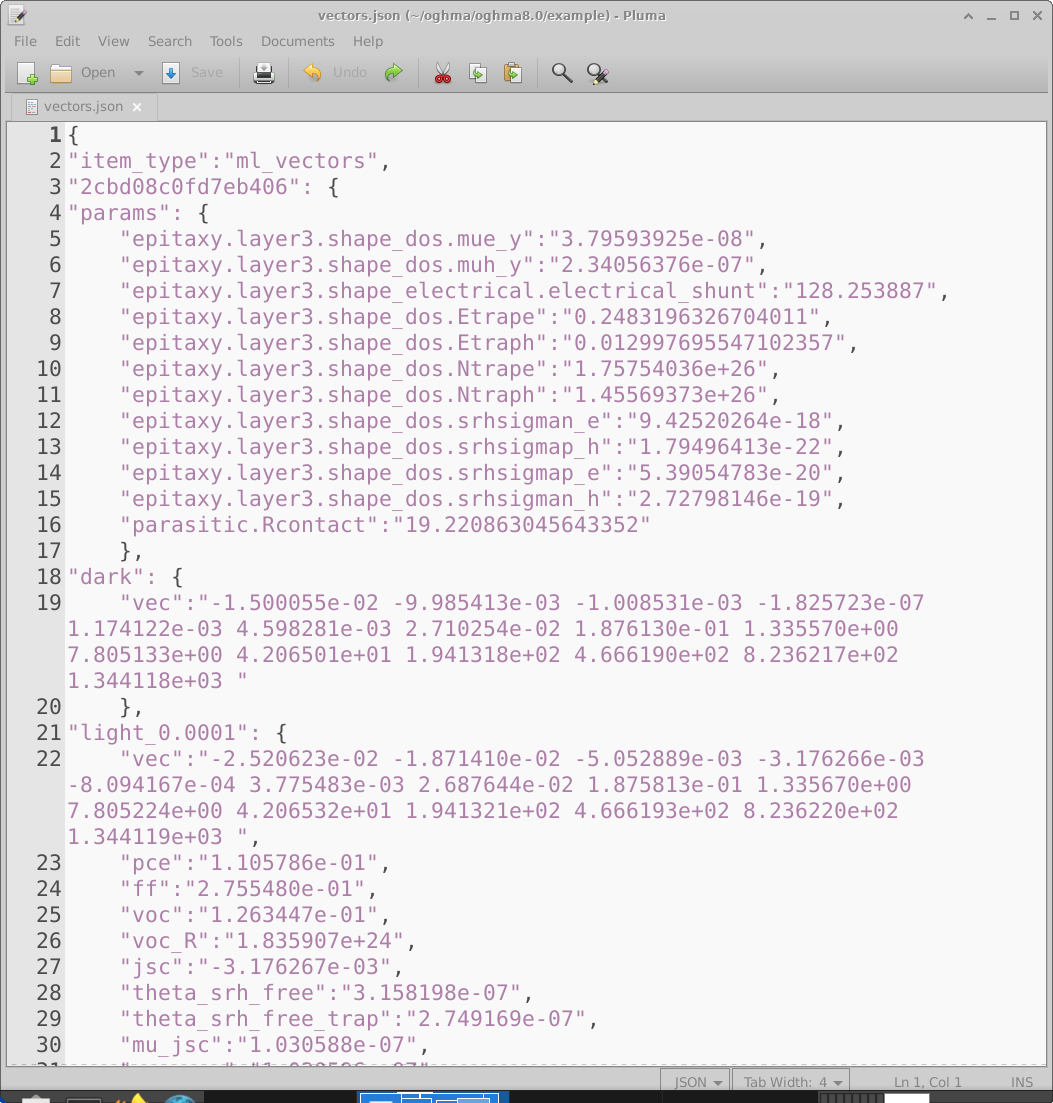
一旦仿真完成,原始 OghmaNano 输出必须转换为一个单独的 vectors 文件, 以便用于训练机器学习模型。在主 Machine learning 窗口中单击 Build vectors 图标 (18.2) 会使 OghmaNano 打开每个虚拟器件目录,提取所请求的输出,并将其编译为 单个 vectors.json 文件。该文件的一个示例如 18.11 所示。
向量文件是一个 JSON 文档,包含监督学习所需的全部信息。每个
虚拟器件都作为一个独立条目出现。例如,标记为
2cbd08c0fd7eb406(第 3 行)的条目在 params 部分下包含为该虚拟器件随机
选择的电学参数。随后是提取出的输入向量,例如暗态 JV 向量(第 19 行)
以及 0.0001 Suns 下的受光照 JV 向量(第 22 行)。每个向量中的数值单位直接继承自
其提取来源文件。在本例中,这些向量取自 jv.dat,该文件存储的是作为电压函数的
电流密度,单位为 \(A\,m^{-2}\),因此向量值的单位也是
\(A\,m^{-2}\)。在输入向量之后,还会存储附加的标量输出(例如 PCE),
以便使用。
该文件中将为每个生成的虚拟器件包含一个条目。一旦生成了 vectors.json, 它就可以作为您所选择的机器学习工作流程的训练数据集。有些用户觉得在将数据转换为 CSV 后再将其 导入 TensorFlow 更方便;这可以使用标准 Python 库完成。
8. 从数据集到机器学习
前面的章节描述了如何使用 OghmaNano 以 JSON 格式生成完整的机器学习数据集。 到这一步,数据生成流程已经完成:对于每个虚拟器件,文件中都包含 随机选择的模型参数以及编码为输入向量的对应仿真输出。
下一步是将这些数据导入您所选择的机器学习框架。
在实践中,这通常意味着读取 vectors.json 文件并将其转换为
诸如 CSV 之类的表格格式,以便用于训练、验证和测试。
这种转换可以使用标准脚本工具(例如 Python)直接完成。
一旦完成转换,这些数据就可以用来训练神经网络或其他回归模型,使用 诸如 TensorFlow、PyTorch 或类似库之类的机器学习框架实现。 从这一点开始,网络架构、损失函数和训练策略的选择取决于具体应用, 并且独立于 OghmaNano。
通过这种方式,OghmaNano 提供了一条完整且自动化的流程,用于生成物理上自洽的 训练数据,而后续的机器学习模型开发与优化则完全由 用户控制。